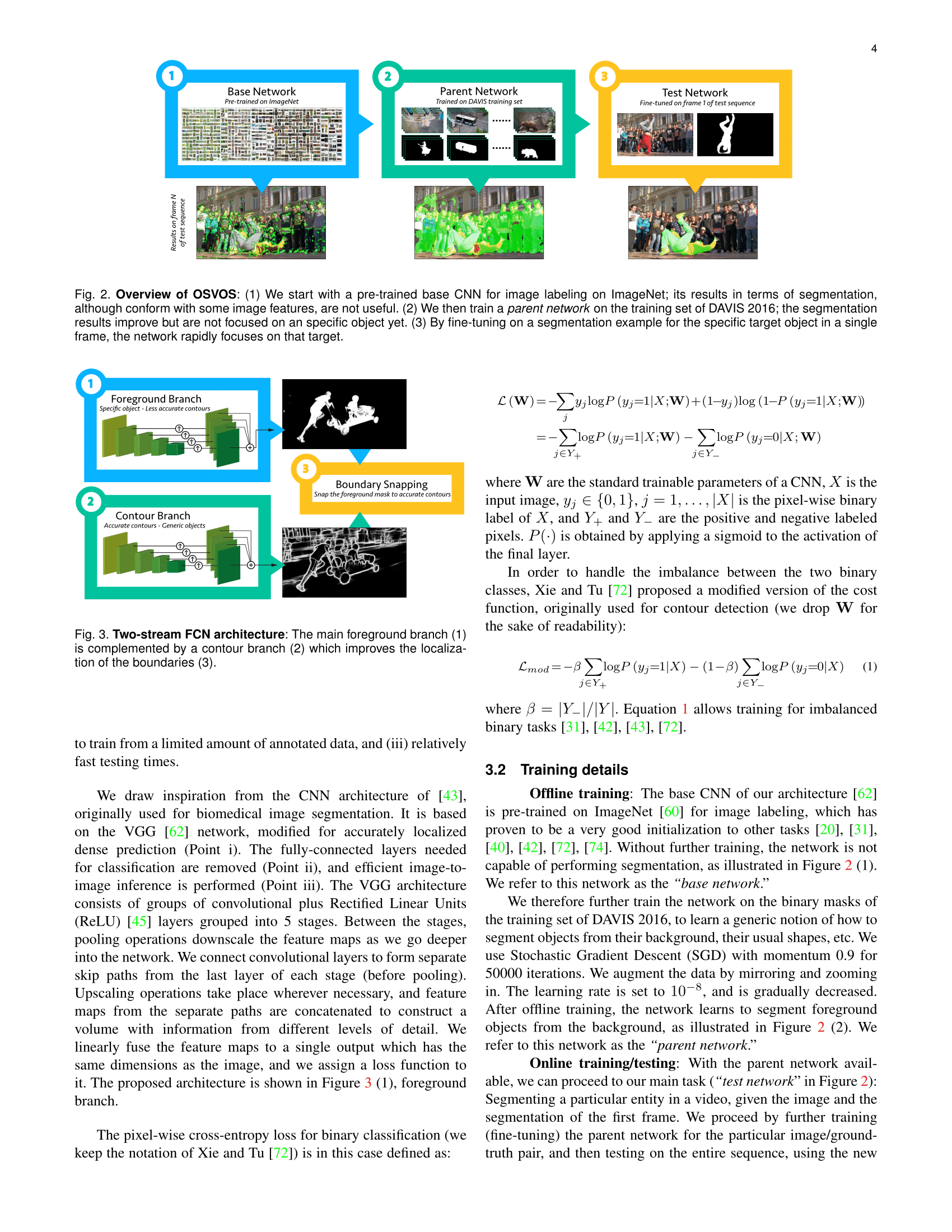
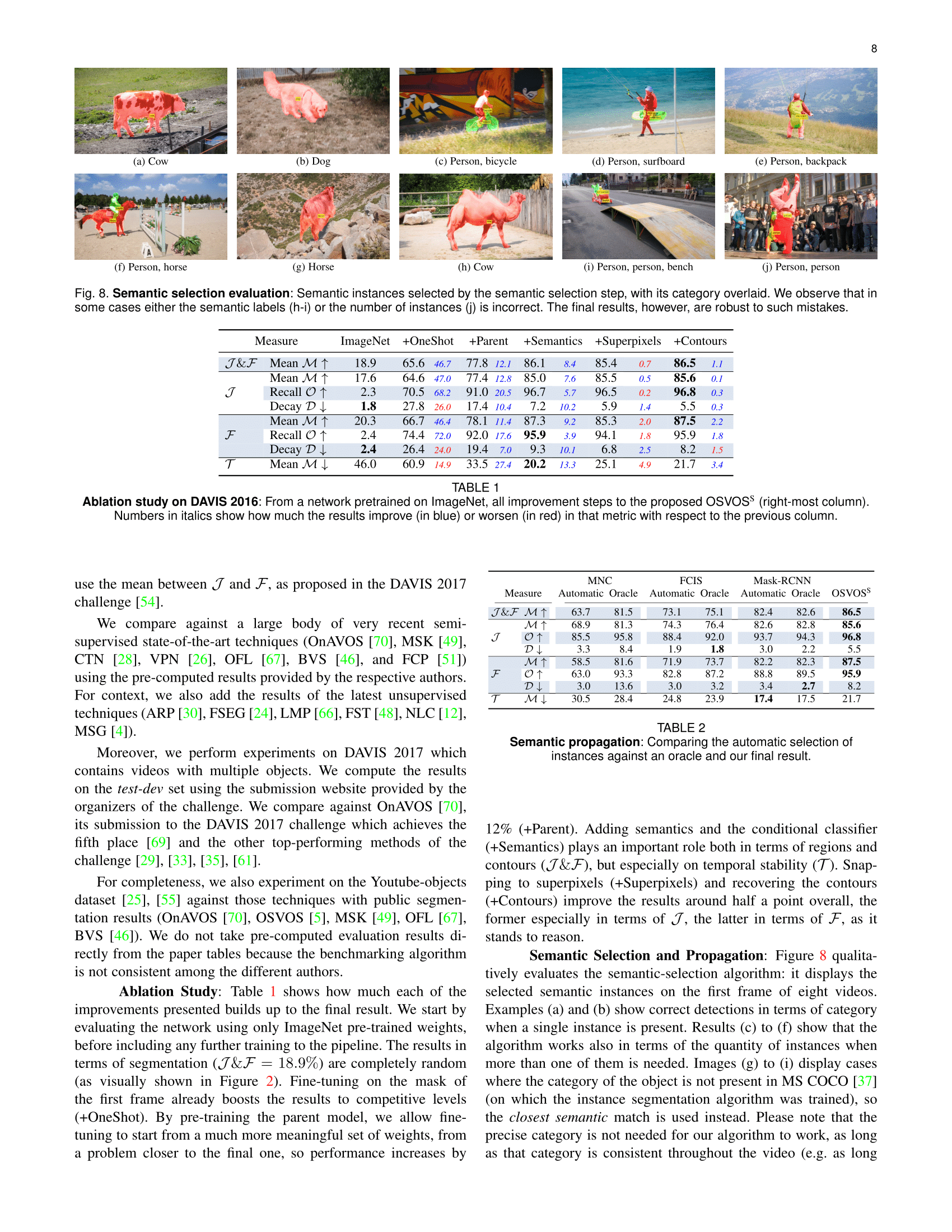
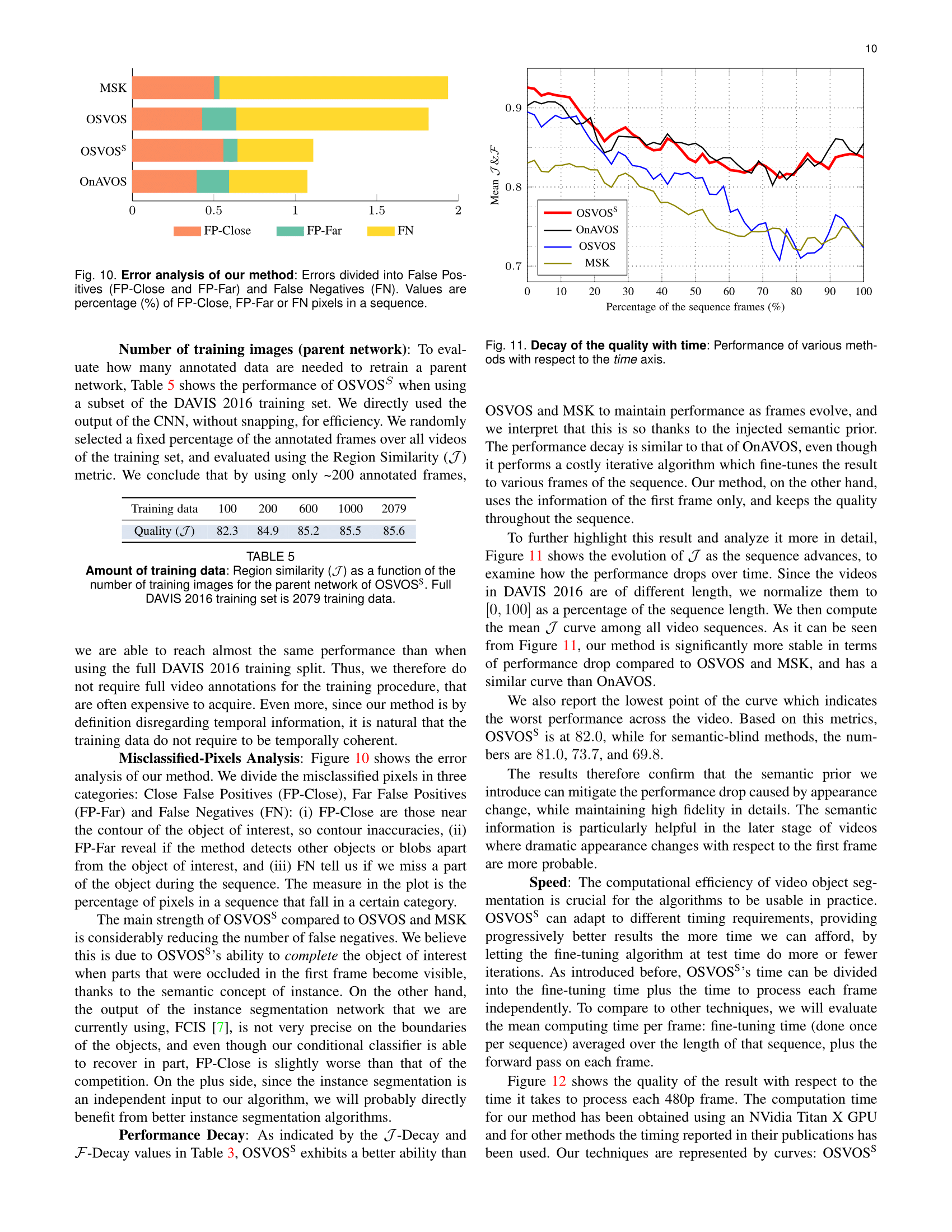
Publication










K.K. Maninis*,
S. Caelles*,
Y.Chen,
J. Pont-Tuset,
L. Leal-Taixé,
D. Cremers, and
L. Van Gool
Video Object Segmentation Without Temporal Information, Transactions of Pattern Analysis and Machine Intelligence (T-PAMI), 2018.
[BibTeX] [PDF]
Video Object Segmentation Without Temporal Information, Transactions of Pattern Analysis and Machine Intelligence (T-PAMI), 2018.
[BibTeX] [PDF]
@Article{Man+18b,
Author = {Kevis-Kokitsi Maninis and Sergi Caelles and Yuhua Chen and Jordi Pont-Tuset and Laura Leal-Taix\'e and Daniel Cremers and Luc {Van Gool}},
Title = {Video Object Segmentation Without Temporal Information},
Journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
Year = {2018}
}







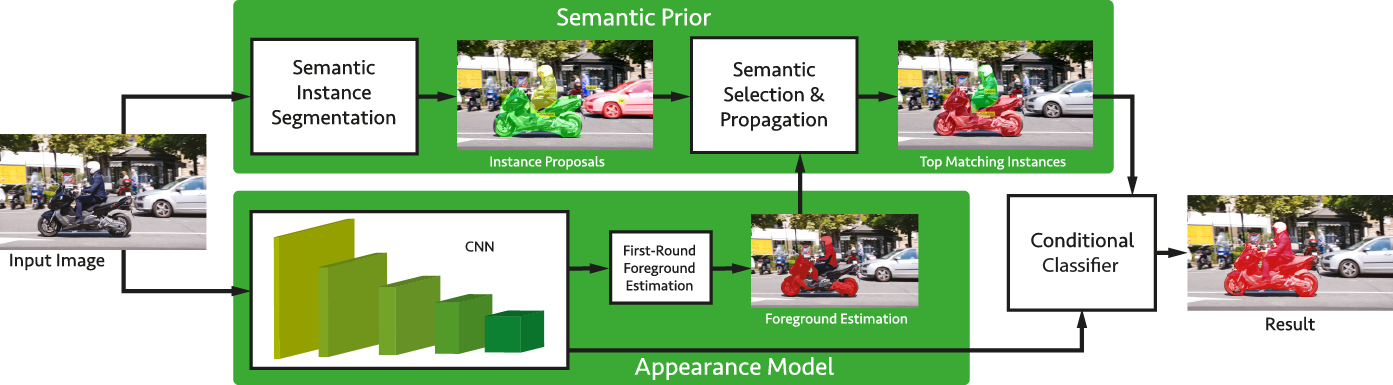
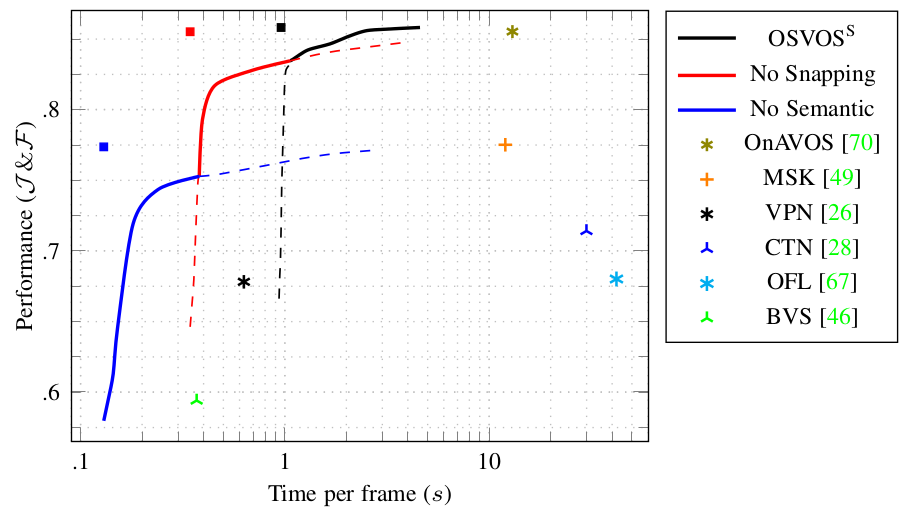
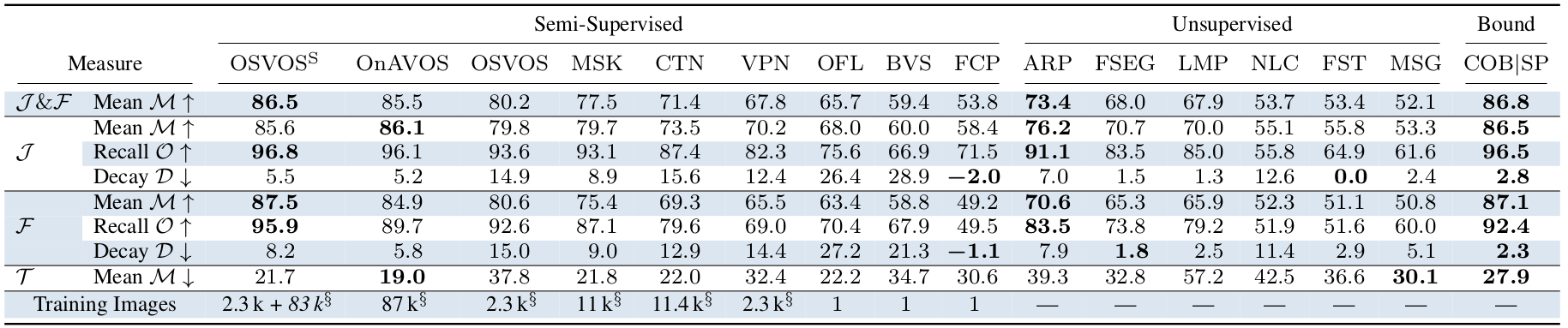 Below the per-sequence results of OSVOS-S compared to the previous state of the art.
Below the per-sequence results of OSVOS-S compared to the previous state of the art.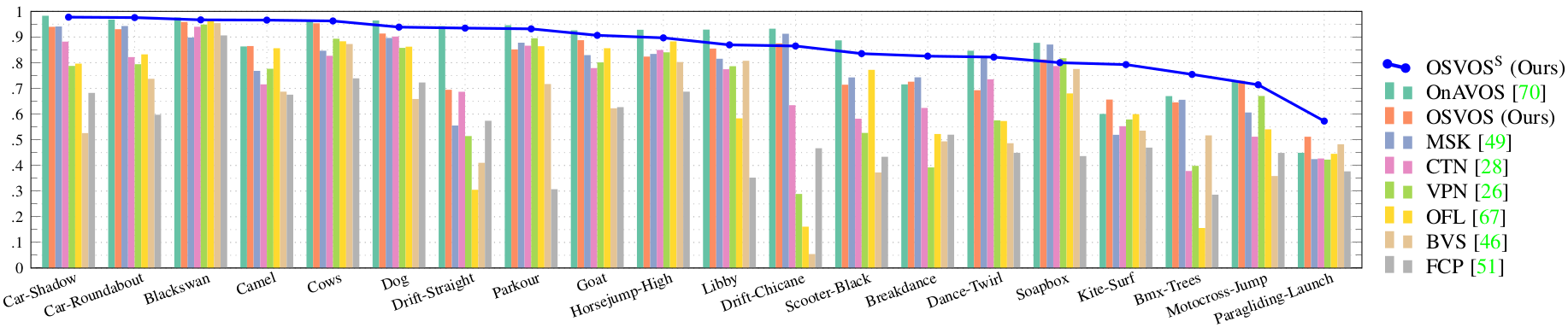 In terms of speed, below the plot of quality versus time per frame.
In terms of speed, below the plot of quality versus time per frame.