Computer Vision Laboratory, ETH Zurich
Switzerland, 2017-2021
| Andrey Ignatov | Nikolay Kobyshev | Radu Timofte | Kenneth Vanhoey | Luc Van Gool |
| ihnatova@vision.ee.ethz.ch | nk@vision.ee.ethz.ch | timofter@vision.ee.ethz.ch | vanhoey@vision.ee.ethz.ch | vangool@vision.ee.ethz.ch |

Abstract: Low-end and compact mobile cameras demonstrate limited photo quality mainly due to space, hardware and budget constraints. In this work, we propose a deep learning solution that translates photos taken by cameras with limited capabilities into DSLR-quality photos automatically. We tackle this problem by introducing a weakly supervised photo enhancer (WESPE) - a novel image-to-image GAN-based architecture. The proposed model is trained by weakly supervised learning: unlike previous works, there is no need for strong supervision in the form of a large annotated dataset of aligned original/enhanced photo pairs. The sole requirement is two distinct datasets: one from the source camera, and one composed of arbitrary high-quality images - the visual content they exhibit may be unrelated. Hence, our solution is repeatable for any camera: collecting the data and training can be achieved in a couple of hours. Our experiments on the DPED, Kitti and Cityscapes datasets as well as on photos from several generations of smartphones demonstrate that WESPE produces comparable qualitative results with state-of-the-art strongly supervised methods.
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
 Original
Original
 Modified
Modified
The first part of experiments is conducted on three publicly available datasets: DPED, Cityscapes and Kitti. The first dataset consists of photos from three smartphones (iPhone 3GS, BlackBerry Passport, Sony Xperia Z), two other datasets were collected using low-end cameras installed in the cars and are intended for semantic labeling and autonomous driving tasks.
Additionally, the proposed approach was tested on photos from several common smartphones: iPhone 6, Huawei P9, HTC One M9, Meizu M3s, Xiaomi Redmi 3X and Nexus 5X. For each phone, between 600 and 1500 training images were collected within one day.
The proposed solution consists of five Convolutional Neural Networks. The first network is a
| ● |
We introduce the |
| ● |
The enhanced image should have bright and vivid colors. To measure its color quality, we train an |
| ● |
A separate |
Finally, these losses are summed, and the presented system is trained as a whole to minimize the final weighted loss.
Note that after the system is trained,
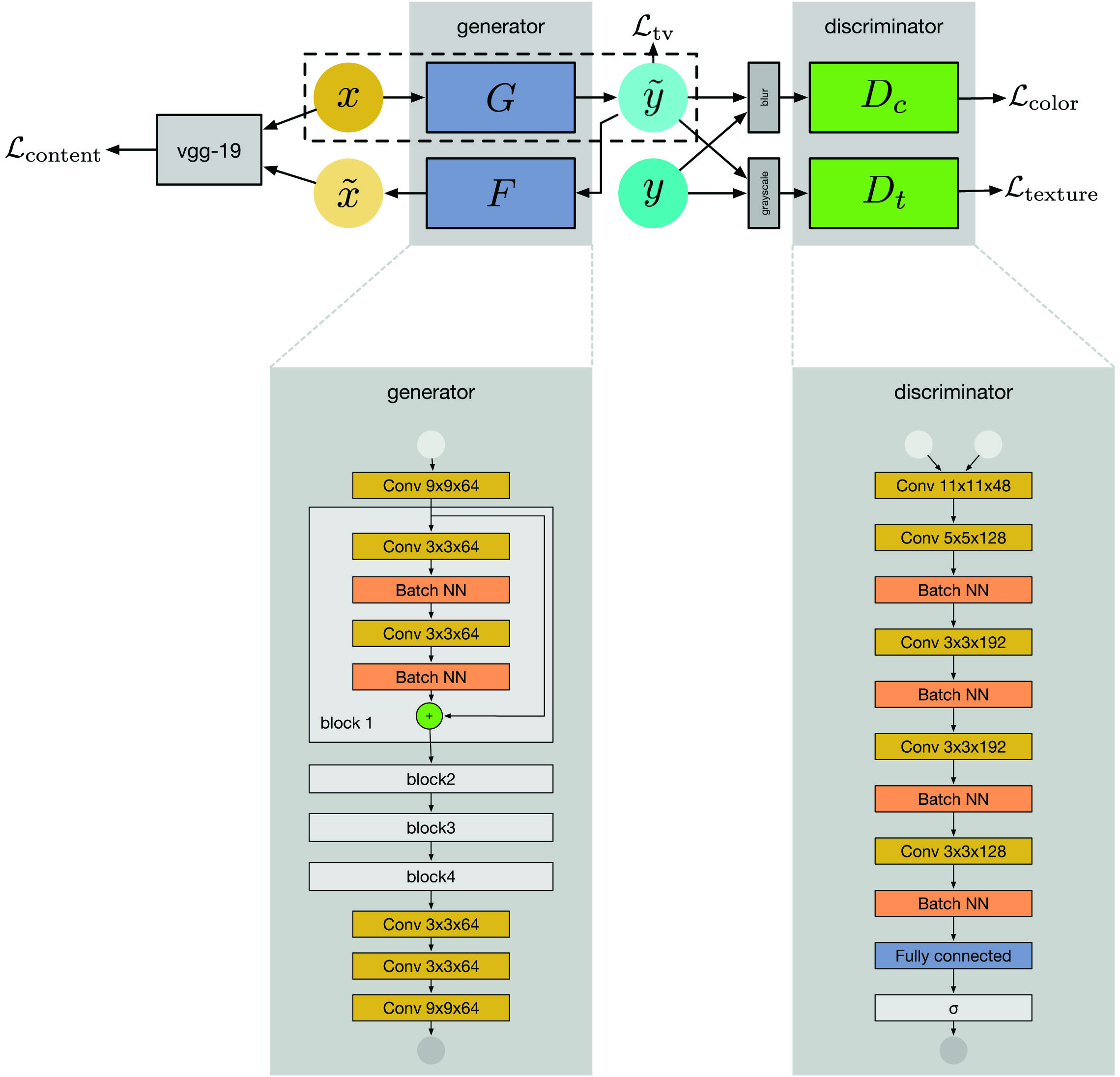
"WESPE: Weakly Supervised Photo Enhancer for Digital Cameras",
In
Computer Vision Laboratory, ETH Zurich
Switzerland, 2017-2021